Data Analysis 2 - Data Wrangling
Learning Objectives
- Describe the purpose of the
dplyrpackage.- Select certain columns in a data frame with the
selectfunction.- Select certain rows in a data frame according to filtering conditions with the
filterfunction.- Link the output of one
dplyrfunction to the input of another function with the “pipe” operator%>%.- Add new columns to a data frame that are functions of existing columns with the
mutatefunction.- Sort data frames using the
arrange()function.- Use the split-apply-combine concept for data analysis.
- Use
summarize,group_by, andcountto split a data frame into groups of observations, apply summary statistics for each group, and then combine the results.- Export a data frame to a .csv file.
Suggested Readings
- Chapter 5 of “R for Data Science”, by Garrett Grolemund and Hadley Wickham
dplyrcheatsheet
R Setup
Before we get started, let’s set up our analysis environment:
- Open up your “data-analysis-tutorial” R Project that you created in the last lesson - if you didn’t do this, go back and do it now.
- Create a new
.Rfile (File > New File > R Script), and save it as “data_wrangling.R” inside your “data-analysis-tutorial” R Project folder. - Use the
download.file()function to download thewildlife_impacts.csvdataset, and save it in thedatafolder in your R Project:
download.file(
url = "https://github.com/emse6574-gwu/2019-Fall/raw/gh-pages/data/wildlife_impacts.csv",
destfile = file.path('data', 'wildlife_impacts.csv')
)For this lesson, we are going to use the FAA Wildlife Strike Database, which contains records of reported wildlife strikes with aircraft since 1990. Since aircraft-wildlife impacts are voluntarily reported, the database only contains information from airlines, airports, pilots, and other sources and does not represent all strikes. Each row in the dataset holds information for a single strike event with the following columns:
| Variable | Class | Description |
|---|---|---|
| incident_date | date | Date of incident |
| state | character | State |
| airport_id | character | ICAO Airport ID |
| airport | character | Airport Name |
| operator | character | Operator/Airline |
| atype | character | Airline type |
| type_eng | character | Engine type |
| species_id | character | Species ID |
| species | character | Species |
| damage | character | Damage: N None M Minor, M Uncertain, S Substantial, D Destroyed |
| num_engs | character | Number of engines |
| incident_month | double | Incident month |
| incident_year | double | Incident year |
| time_of_day | character | Incident Time of day |
| time | double | Incident time |
| height | double | Plane height at impact (feet) |
| speed | double | Plane speed at impact (knots) |
| phase_of_flt | character | Phase of flight at impact |
| sky | character | Sky condition |
| precip | character | Precipitation |
| cost_repairs_infl_adj | double | Cost of repairs adjusted for inflation |
Let’s load our libraries and read in the data:
library(readr)
library(dplyr)
df <- read_csv(file.path('data', 'wildlife_impacts.csv'))Just like in the last lesson, a good starting point when working with a new dataset is to view some quick summaries. Here’s another summary function (glimpse()) that is similar to str():
glimpse(df)## Rows: 56,978
## Columns: 21
## $ incident_date [3m[90m<dttm>[39m[23m 2018-12-31, 2018-12-29, 2018-12-29, 2018-12-27…
## $ state [3m[90m<chr>[39m[23m "FL", "IN", "N/A", "N/A", "N/A", "FL", "FL", "N…
## $ airport_id [3m[90m<chr>[39m[23m "KMIA", "KIND", "ZZZZ", "ZZZZ", "ZZZZ", "KMIA",…
## $ airport [3m[90m<chr>[39m[23m "MIAMI INTL", "INDIANAPOLIS INTL ARPT", "UNKNOW…
## $ operator [3m[90m<chr>[39m[23m "AMERICAN AIRLINES", "AMERICAN AIRLINES", "AMER…
## $ atype [3m[90m<chr>[39m[23m "B-737-800", "B-737-800", "UNKNOWN", "B-737-900…
## $ type_eng [3m[90m<chr>[39m[23m "D", "D", NA, "D", "D", "D", "D", "D", "D", "D"…
## $ species_id [3m[90m<chr>[39m[23m "UNKBL", "R", "R2004", "N5205", "J2139", "UNKB"…
## $ species [3m[90m<chr>[39m[23m "Unknown bird - large", "Owls", "Short-eared ow…
## $ damage [3m[90m<chr>[39m[23m "M?", "N", NA, "M?", "M?", "N", "N", "N", "N", …
## $ num_engs [3m[90m<dbl>[39m[23m 2, 2, NA, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2…
## $ incident_month [3m[90m<dbl>[39m[23m 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12,…
## $ incident_year [3m[90m<dbl>[39m[23m 2018, 2018, 2018, 2018, 2018, 2018, 2018, 2018,…
## $ time_of_day [3m[90m<chr>[39m[23m "Day", "Night", NA, NA, NA, "Day", "Night", NA,…
## $ time [3m[90m<dbl>[39m[23m 1207, 2355, NA, NA, NA, 955, 948, NA, NA, 1321,…
## $ height [3m[90m<dbl>[39m[23m 700, 0, NA, NA, NA, NA, 600, NA, NA, 0, NA, 0, …
## $ speed [3m[90m<dbl>[39m[23m 200, NA, NA, NA, NA, NA, 145, NA, NA, 130, NA, …
## $ phase_of_flt [3m[90m<chr>[39m[23m "Climb", "Landing Roll", NA, NA, NA, "Approach"…
## $ sky [3m[90m<chr>[39m[23m "Some Cloud", NA, NA, NA, NA, NA, "Some Cloud",…
## $ precip [3m[90m<chr>[39m[23m "None", NA, NA, NA, NA, NA, "None", NA, NA, "No…
## $ cost_repairs_infl_adj [3m[90m<dbl>[39m[23m NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…Wow, there have been 56,978 reported wildlife strikes over the 29 period from 1990 to 2019! On a daily average that comes out to:
nrow(df) / (2019 - 1990) / 365## [1] 5.3829…over 5 strikes per day!
Data wrangling with dplyr

“Data Wrangling” refers to the art of getting your data into R in a useful form for visualization and modeling. Wrangling is the first step in the general data science process:
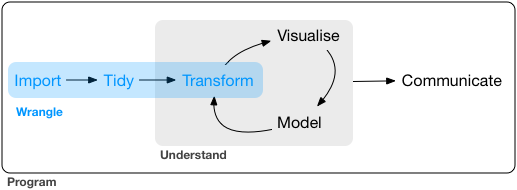
What is dplyr
As we saw in the last section, we can use brackets ([]) to access elements of a data frame. While this is handy, it can be cumbersome and difficult to read, especially for complicated operations.
Enter dplyr
The dplyr package was designed to make tabular data wrangling easier to perform and read. It pairs nicely with other libraries, such as ggplot2 for visualizing data (which we’ll cover next week). Together, dplyr, ggplot2, and a handful of other packages make up what is known as the “Tidyverse” - an opinionated collection of R packages designed for data science. You can load all of the tidyverse packages at once using the library(tidyverse) command, but for now we’re just going to install and use each package one at a time - starting with dplyr:
install.packages("dplyr")In this lesson, we are going to learn some of the most common dplyr functions:
select(): subset columnsfilter(): subset rows on conditionsmutate(): create new columns by using information from other columnsarrange(): sort resultsgroup_by(): group data to perform grouped operationssummarize(): create summary statistics (usually on grouped data)count(): count discrete rows
Select columns with select()
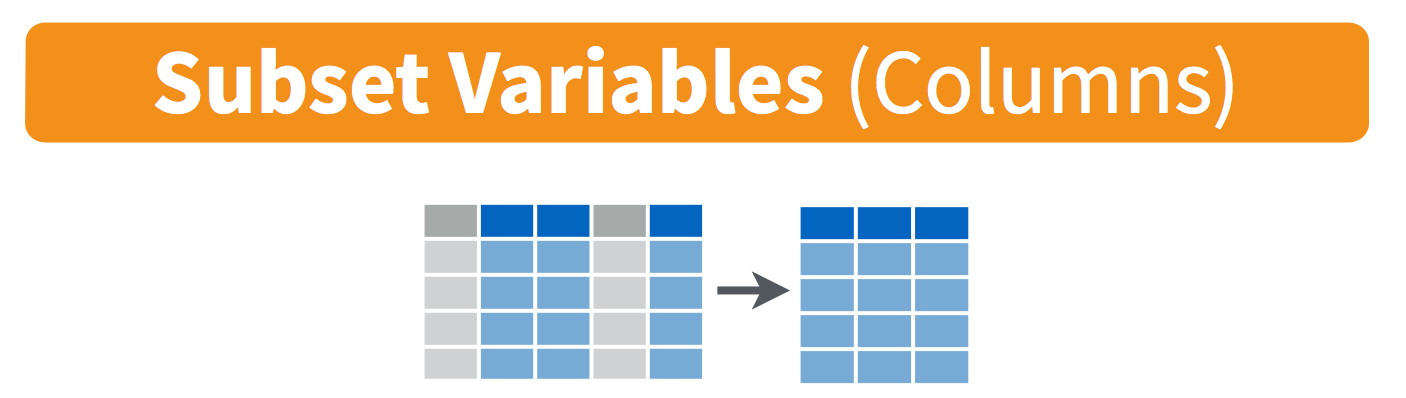
To select specific columns, use select(). The first argument to this function is the data frame (df), and the subsequent arguments are the columns to keep:
# Select only a few columns
select(df, state, damage, time_of_day)## [90m# A tibble: 56,978 x 3[39m
## state damage time_of_day
## [3m[90m<chr>[39m[23m [3m[90m<chr>[39m[23m [3m[90m<chr>[39m[23m
## [90m 1[39m FL M? Day
## [90m 2[39m IN N Night
## [90m 3[39m N/A [31mNA[39m [31mNA[39m
## [90m 4[39m N/A M? [31mNA[39m
## [90m 5[39m N/A M? [31mNA[39m
## [90m 6[39m FL N Day
## [90m 7[39m FL N Night
## [90m 8[39m N/A N [31mNA[39m
## [90m 9[39m N/A N [31mNA[39m
## [90m10[39m FL N Day
## [90m# … with 56,968 more rows[39mTo select all columns except certain ones, put a - sign in front of the variable to exclude it:
select(df, -state, -damage, -time_of_day)## [90m# A tibble: 56,978 x 18[39m
## incident_date airport_id airport operator atype type_eng species_id
## [3m[90m<dttm>[39m[23m [3m[90m<chr>[39m[23m [3m[90m<chr>[39m[23m [3m[90m<chr>[39m[23m [3m[90m<chr>[39m[23m [3m[90m<chr>[39m[23m [3m[90m<chr>[39m[23m
## [90m 1[39m 2018-12-31 [90m00:00:00[39m KMIA MIAMI … AMERICA… B-73… D UNKBL
## [90m 2[39m 2018-12-29 [90m00:00:00[39m KIND INDIAN… AMERICA… B-73… D R
## [90m 3[39m 2018-12-29 [90m00:00:00[39m ZZZZ UNKNOWN AMERICA… UNKN… [31mNA[39m R2004
## [90m 4[39m 2018-12-27 [90m00:00:00[39m ZZZZ UNKNOWN AMERICA… B-73… D N5205
## [90m 5[39m 2018-12-27 [90m00:00:00[39m ZZZZ UNKNOWN AMERICA… B-73… D J2139
## [90m 6[39m 2018-12-27 [90m00:00:00[39m KMIA MIAMI … AMERICA… A-319 D UNKB
## [90m 7[39m 2018-12-27 [90m00:00:00[39m KMCO ORLAND… AMERICA… A-321 D UNKBS
## [90m 8[39m 2018-12-26 [90m00:00:00[39m ZZZZ UNKNOWN AMERICA… B-73… D ZT001
## [90m 9[39m 2018-12-23 [90m00:00:00[39m ZZZZ UNKNOWN AMERICA… A-321 D ZT101
## [90m10[39m 2018-12-23 [90m00:00:00[39m KFLL FORT L… AMERICA… B-73… D I1301
## [90m# … with 56,968 more rows, and 11 more variables: species [3m[90m<chr>[90m[23m,[39m
## [90m# num_engs [3m[90m<dbl>[90m[23m, incident_month [3m[90m<dbl>[90m[23m, incident_year [3m[90m<dbl>[90m[23m, time [3m[90m<dbl>[90m[23m,[39m
## [90m# height [3m[90m<dbl>[90m[23m, speed [3m[90m<dbl>[90m[23m, phase_of_flt [3m[90m<chr>[90m[23m, sky [3m[90m<chr>[90m[23m, precip [3m[90m<chr>[90m[23m,[39m
## [90m# cost_repairs_infl_adj [3m[90m<dbl>[90m[23m[39mSome additional options to select columns based on a specific criteria include:
ends_with()= Select columns that end with a character stringcontains()= Select columns that contain a character stringmatches()= Select columns that match a regular expressionone_of()= Select column names that are from a group of names
Select rows with filter()
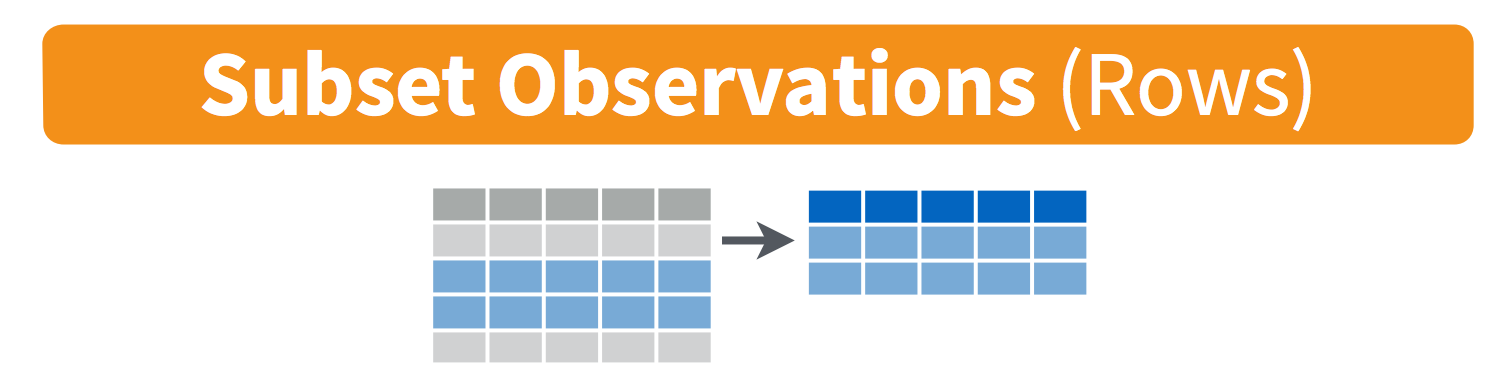
Filter the rows for wildlife impacts that occurred in DC:
filter(df, state == 'DC')## [90m# A tibble: 1,228 x 21[39m
## incident_date state airport_id airport operator atype type_eng
## [3m[90m<dttm>[39m[23m [3m[90m<chr>[39m[23m [3m[90m<chr>[39m[23m [3m[90m<chr>[39m[23m [3m[90m<chr>[39m[23m [3m[90m<chr>[39m[23m [3m[90m<chr>[39m[23m
## [90m 1[39m 2018-10-23 [90m00:00:00[39m DC KDCA RONALD… AMERICA… B-73… D
## [90m 2[39m 2018-10-17 [90m00:00:00[39m DC KDCA RONALD… AMERICA… B-73… D
## [90m 3[39m 2018-10-16 [90m00:00:00[39m DC KDCA RONALD… AMERICA… B-73… D
## [90m 4[39m 2018-10-12 [90m00:00:00[39m DC KDCA RONALD… AMERICA… B-73… D
## [90m 5[39m 2018-09-04 [90m00:00:00[39m DC KDCA RONALD… AMERICA… A-319 D
## [90m 6[39m 2018-09-01 [90m00:00:00[39m DC KDCA RONALD… AMERICA… A-321 D
## [90m 7[39m 2018-08-31 [90m00:00:00[39m DC KIAD WASHIN… AMERICA… A-319 D
## [90m 8[39m 2018-08-23 [90m00:00:00[39m DC KDCA RONALD… AMERICA… EMB-… D
## [90m 9[39m 2018-08-13 [90m00:00:00[39m DC KIAD WASHIN… AMERICA… MD-82 D
## [90m10[39m 2018-08-01 [90m00:00:00[39m DC KIAD WASHIN… AMERICA… CRJ7… D
## [90m# … with 1,218 more rows, and 14 more variables: species_id [3m[90m<chr>[90m[23m,[39m
## [90m# species [3m[90m<chr>[90m[23m, damage [3m[90m<chr>[90m[23m, num_engs [3m[90m<dbl>[90m[23m, incident_month [3m[90m<dbl>[90m[23m,[39m
## [90m# incident_year [3m[90m<dbl>[90m[23m, time_of_day [3m[90m<chr>[90m[23m, time [3m[90m<dbl>[90m[23m, height [3m[90m<dbl>[90m[23m,[39m
## [90m# speed [3m[90m<dbl>[90m[23m, phase_of_flt [3m[90m<chr>[90m[23m, sky [3m[90m<chr>[90m[23m, precip [3m[90m<chr>[90m[23m,[39m
## [90m# cost_repairs_infl_adj [3m[90m<dbl>[90m[23m[39mFilter the rows for wildlife impacts that cost more than $1 million in damages:
filter(df, cost_repairs_infl_adj > 10^6)## [90m# A tibble: 41 x 21[39m
## incident_date state airport_id airport operator atype type_eng
## [3m[90m<dttm>[39m[23m [3m[90m<chr>[39m[23m [3m[90m<chr>[39m[23m [3m[90m<chr>[39m[23m [3m[90m<chr>[39m[23m [3m[90m<chr>[39m[23m [3m[90m<chr>[39m[23m
## [90m 1[39m 2015-05-26 [90m00:00:00[39m N/A SVMI SIMON … AMERICA… B-73… D
## [90m 2[39m 2015-04-25 [90m00:00:00[39m FL KJAX JACKSO… AMERICA… A-319 D
## [90m 3[39m 2015-04-02 [90m00:00:00[39m MA KBOS GENERA… AMERICA… B-73… D
## [90m 4[39m 2001-04-02 [90m00:00:00[39m N/A LFPG CHARLE… AMERICA… B-76… D
## [90m 5[39m 2015-10-08 [90m00:00:00[39m WA KSEA SEATTL… DELTA A… A-330 D
## [90m 6[39m 2015-09-23 [90m00:00:00[39m UT KSLC SALT L… DELTA A… B-73… D
## [90m 7[39m 2008-10-25 [90m00:00:00[39m UT KSLC SALT L… DELTA A… DC-9… D
## [90m 8[39m 2007-12-02 [90m00:00:00[39m N/A GOOY DAKAY-… DELTA A… B-76… D
## [90m 9[39m 2007-11-22 [90m00:00:00[39m N/A LFMN NICE C… DELTA A… B-76… D
## [90m10[39m 2011-07-30 [90m00:00:00[39m CA KBUR BOB HO… SOUTHWE… B-73… D
## [90m# … with 31 more rows, and 14 more variables: species_id [3m[90m<chr>[90m[23m, species [3m[90m<chr>[90m[23m,[39m
## [90m# damage [3m[90m<chr>[90m[23m, num_engs [3m[90m<dbl>[90m[23m, incident_month [3m[90m<dbl>[90m[23m, incident_year [3m[90m<dbl>[90m[23m,[39m
## [90m# time_of_day [3m[90m<chr>[90m[23m, time [3m[90m<dbl>[90m[23m, height [3m[90m<dbl>[90m[23m, speed [3m[90m<dbl>[90m[23m,[39m
## [90m# phase_of_flt [3m[90m<chr>[90m[23m, sky [3m[90m<chr>[90m[23m, precip [3m[90m<chr>[90m[23m, cost_repairs_infl_adj [3m[90m<dbl>[90m[23m[39mSequence operations with pipes (%>%)
 (logo is a reference to The Treachery of Images)
(logo is a reference to The Treachery of Images)
What if you want to select and filter at the same time? Well, one way to do this is to use intermediate steps. To do this, you first create a temporary data frame and then use that as input to the next function, like this:
dc_impacts <- filter(df, state == 'DC')
dc_impacts_airlineTime <- select(dc_impacts, operator, time, time_of_day)
head(dc_impacts_airlineTime)## [90m# A tibble: 6 x 3[39m
## operator time time_of_day
## [3m[90m<chr>[39m[23m [3m[90m<dbl>[39m[23m [3m[90m<chr>[39m[23m
## [90m1[39m AMERICAN AIRLINES [4m2[24m130 Night
## [90m2[39m AMERICAN AIRLINES [4m2[24m043 Night
## [90m3[39m AMERICAN AIRLINES 730 Dawn
## [90m4[39m AMERICAN AIRLINES [4m2[24m245 Night
## [90m5[39m AMERICAN AIRLINES [4m2[24m150 Night
## [90m6[39m AMERICAN AIRLINES [4m2[24m022 NightThis works, but it can also clutter up your workspace with lots of objects with different names.
Another approach is to use pipes, which is a more recent addition to R. Pipes let you take the output of one function and send it directly to the next, which is useful when you need to do many things to the same dataset.
The pipe operator is %>% and comes from the magrittr package, which is installed automatically with dplyr. If you use RStudio, you can type the pipe with Ctrl + Shift + M if you have a PC or Cmd + Shift + M if you have a Mac. Here’s the same thing as the previous example but with pipes:
df %>%
filter(state == 'DC') %>%
select(operator, time, time_of_day) %>%
head()## [90m# A tibble: 6 x 3[39m
## operator time time_of_day
## [3m[90m<chr>[39m[23m [3m[90m<dbl>[39m[23m [3m[90m<chr>[39m[23m
## [90m1[39m AMERICAN AIRLINES [4m2[24m130 Night
## [90m2[39m AMERICAN AIRLINES [4m2[24m043 Night
## [90m3[39m AMERICAN AIRLINES 730 Dawn
## [90m4[39m AMERICAN AIRLINES [4m2[24m245 Night
## [90m5[39m AMERICAN AIRLINES [4m2[24m150 Night
## [90m6[39m AMERICAN AIRLINES [4m2[24m022 NightIn the above code, we use the pipe to send the df data frame first through filter() to keep only rows from DC, and then through select() to keep only the columns operator, time, and time_of_day.
Since %>% takes the object on its left and passes it as the first argument to the function on its right, we don’t need to explicitly include the data frame as an argument to the filter() and select() functions.
Consider reading the %>% operator as the words “…and then…”. For instance, in the above example I would read the code as “First, filter to only data from DC, and then select the columns operator, time, and time_of_day, and then show the first 6 rows.”
Here’s another analogy:
Without Pipes:
leave_house(get_dressed(get_out_of_bed(wake_up(me))))With Pipes:
me %>%
wake_up %>%
get_out_of_bed %>%
get_dressed %>%
leave_houseIn the above example, adding pipes makes the flow of operations easier to read from left to right, with the %>% operator reading as “…and then…”
If you want to create a new object with the output of a “pipeline”, you just put the object name at the start of the first pipe:
dc_impacts <- df %>%
filter(state == 'DC') %>%
select(operator, time, time_of_day)
head(dc_impacts)## [90m# A tibble: 6 x 3[39m
## operator time time_of_day
## [3m[90m<chr>[39m[23m [3m[90m<dbl>[39m[23m [3m[90m<chr>[39m[23m
## [90m1[39m AMERICAN AIRLINES [4m2[24m130 Night
## [90m2[39m AMERICAN AIRLINES [4m2[24m043 Night
## [90m3[39m AMERICAN AIRLINES 730 Dawn
## [90m4[39m AMERICAN AIRLINES [4m2[24m245 Night
## [90m5[39m AMERICAN AIRLINES [4m2[24m150 Night
## [90m6[39m AMERICAN AIRLINES [4m2[24m022 NightSort rows with arrange()
Use the arrange() function to sort a data frame by a column. For example, if you wanted to view the least expensive accidents, you could arrange the data frame by the variable cost_repairs_infl_adj:
# Arrange by least expensive accident
df %>%
arrange(cost_repairs_infl_adj)## [90m# A tibble: 56,978 x 21[39m
## incident_date state airport_id airport operator atype type_eng
## [3m[90m<dttm>[39m[23m [3m[90m<chr>[39m[23m [3m[90m<chr>[39m[23m [3m[90m<chr>[39m[23m [3m[90m<chr>[39m[23m [3m[90m<chr>[39m[23m [3m[90m<chr>[39m[23m
## [90m 1[39m 2013-09-05 [90m00:00:00[39m MI KFNT BISHOP… SOUTHWE… B-73… D
## [90m 2[39m 2011-04-17 [90m00:00:00[39m TX KDFW DALLAS… AMERICA… MD-80 D
## [90m 3[39m 2018-07-10 [90m00:00:00[39m NM KABQ ALBUQU… SOUTHWE… B-73… D
## [90m 4[39m 2017-10-31 [90m00:00:00[39m PA KPIT PITTSB… AMERICA… B-73… D
## [90m 5[39m 2014-01-17 [90m00:00:00[39m UT KSLC SALT L… SOUTHWE… B-73… D
## [90m 6[39m 2006-04-28 [90m00:00:00[39m TX KIAH GEORGE… UNITED … B-73… D
## [90m 7[39m 2005-04-13 [90m00:00:00[39m N/A ZZZZ UNKNOWN UNITED … B-76… D
## [90m 8[39m 2004-06-17 [90m00:00:00[39m N/A ZZZZ UNKNOWN UNITED … B-73… D
## [90m 9[39m 2004-04-22 [90m00:00:00[39m N/A ZZZZ UNKNOWN UNITED … B-76… D
## [90m10[39m 2018-10-20 [90m00:00:00[39m TX KDAL DALLAS… SOUTHWE… B-73… D
## [90m# … with 56,968 more rows, and 14 more variables: species_id [3m[90m<chr>[90m[23m,[39m
## [90m# species [3m[90m<chr>[90m[23m, damage [3m[90m<chr>[90m[23m, num_engs [3m[90m<dbl>[90m[23m, incident_month [3m[90m<dbl>[90m[23m,[39m
## [90m# incident_year [3m[90m<dbl>[90m[23m, time_of_day [3m[90m<chr>[90m[23m, time [3m[90m<dbl>[90m[23m, height [3m[90m<dbl>[90m[23m,[39m
## [90m# speed [3m[90m<dbl>[90m[23m, phase_of_flt [3m[90m<chr>[90m[23m, sky [3m[90m<chr>[90m[23m, precip [3m[90m<chr>[90m[23m,[39m
## [90m# cost_repairs_infl_adj [3m[90m<dbl>[90m[23m[39mTo sort in descending order, add the desc() function inside the arrange() function. For example, here are the most expensive accidents:
# Arrange by most expensive accident
df %>%
arrange(desc(cost_repairs_infl_adj))## [90m# A tibble: 56,978 x 21[39m
## incident_date state airport_id airport operator atype type_eng
## [3m[90m<dttm>[39m[23m [3m[90m<chr>[39m[23m [3m[90m<chr>[39m[23m [3m[90m<chr>[39m[23m [3m[90m<chr>[39m[23m [3m[90m<chr>[39m[23m [3m[90m<chr>[39m[23m
## [90m 1[39m 2009-02-03 [90m00:00:00[39m CO KDEN DENVER… UNITED … B-75… D
## [90m 2[39m 2007-11-22 [90m00:00:00[39m N/A LFMN NICE C… DELTA A… B-76… D
## [90m 3[39m 2011-09-26 [90m00:00:00[39m CO KDEN DENVER… UNITED … B-75… D
## [90m 4[39m 2017-07-11 [90m00:00:00[39m CO KDEN DENVER… UNITED … B-73… D
## [90m 5[39m 2008-10-25 [90m00:00:00[39m UT KSLC SALT L… DELTA A… DC-9… D
## [90m 6[39m 2011-07-30 [90m00:00:00[39m CA KBUR BOB HO… SOUTHWE… B-73… D
## [90m 7[39m 2001-12-06 [90m00:00:00[39m MI KDTW DETROI… SOUTHWE… B-73… D
## [90m 8[39m 2003-04-15 [90m00:00:00[39m CA KSFO SAN FR… UNITED … B-73… D
## [90m 9[39m 2005-09-06 [90m00:00:00[39m CO KDEN DENVER… UNITED … B-73… D
## [90m10[39m 2005-04-20 [90m00:00:00[39m N/A ZZZZ UNKNOWN UNITED … B-77… D
## [90m# … with 56,968 more rows, and 14 more variables: species_id [3m[90m<chr>[90m[23m,[39m
## [90m# species [3m[90m<chr>[90m[23m, damage [3m[90m<chr>[90m[23m, num_engs [3m[90m<dbl>[90m[23m, incident_month [3m[90m<dbl>[90m[23m,[39m
## [90m# incident_year [3m[90m<dbl>[90m[23m, time_of_day [3m[90m<chr>[90m[23m, time [3m[90m<dbl>[90m[23m, height [3m[90m<dbl>[90m[23m,[39m
## [90m# speed [3m[90m<dbl>[90m[23m, phase_of_flt [3m[90m<chr>[90m[23m, sky [3m[90m<chr>[90m[23m, precip [3m[90m<chr>[90m[23m,[39m
## [90m# cost_repairs_infl_adj [3m[90m<dbl>[90m[23m[39mCreate new variables with mutate()

You will often need to create new columns based on the values in existing columns. For this use mutate(). For example, let’s create a new variable converting the height variable from feet to miles:
df %>%
mutate(height_miles = height / 5280) %>%
select(height, height_miles)## [90m# A tibble: 56,978 x 2[39m
## height height_miles
## [3m[90m<dbl>[39m[23m [3m[90m<dbl>[39m[23m
## [90m 1[39m 700 0.133
## [90m 2[39m 0 0
## [90m 3[39m [31mNA[39m [31mNA[39m
## [90m 4[39m [31mNA[39m [31mNA[39m
## [90m 5[39m [31mNA[39m [31mNA[39m
## [90m 6[39m [31mNA[39m [31mNA[39m
## [90m 7[39m 600 0.114
## [90m 8[39m [31mNA[39m [31mNA[39m
## [90m 9[39m [31mNA[39m [31mNA[39m
## [90m10[39m 0 0
## [90m# … with 56,968 more rows[39mYou can also create a second new column based on the first new column within the same call of mutate():
df %>%
mutate(height_miles = height / 5280,
height_half_miles = height_miles / 2) %>%
select(height, height_miles, height_half_miles)## [90m# A tibble: 56,978 x 3[39m
## height height_miles height_half_miles
## [3m[90m<dbl>[39m[23m [3m[90m<dbl>[39m[23m [3m[90m<dbl>[39m[23m
## [90m 1[39m 700 0.133 0.066[4m3[24m
## [90m 2[39m 0 0 0
## [90m 3[39m [31mNA[39m [31mNA[39m [31mNA[39m
## [90m 4[39m [31mNA[39m [31mNA[39m [31mNA[39m
## [90m 5[39m [31mNA[39m [31mNA[39m [31mNA[39m
## [90m 6[39m [31mNA[39m [31mNA[39m [31mNA[39m
## [90m 7[39m 600 0.114 0.056[4m8[24m
## [90m 8[39m [31mNA[39m [31mNA[39m [31mNA[39m
## [90m 9[39m [31mNA[39m [31mNA[39m [31mNA[39m
## [90m10[39m 0 0 0
## [90m# … with 56,968 more rows[39mYou’ll notice that the variables created have a lot of NAs - that’s because there are missing data. If you wanted to remove those, you could insert a filter() in the pipe chain:
df %>%
filter(!is.na(height)) %>%
mutate(height_miles = height / 5280) %>%
select(height, height_miles)## [90m# A tibble: 38,940 x 2[39m
## height height_miles
## [3m[90m<dbl>[39m[23m [3m[90m<dbl>[39m[23m
## [90m 1[39m 700 0.133
## [90m 2[39m 0 0
## [90m 3[39m 600 0.114
## [90m 4[39m 0 0
## [90m 5[39m 0 0
## [90m 6[39m 0 0
## [90m 7[39m 500 0.094[4m7[24m
## [90m 8[39m 100 0.018[4m9[24m
## [90m 9[39m 0 0
## [90m10[39m [4m1[24m000 0.189
## [90m# … with 38,930 more rows[39mis.na() is a function that determines whether something is an NA. The ! symbol negates the result, so we’re asking for every row where weight is not an NA.
Split-apply-combine
Many data analysis tasks can be approached using the split-apply-combine paradigm:
- Split the data into groups
- Apply some analysis to each group
- Combine the results.
dplyr makes this very easy through the use of the group_by() function.
The group_by() function
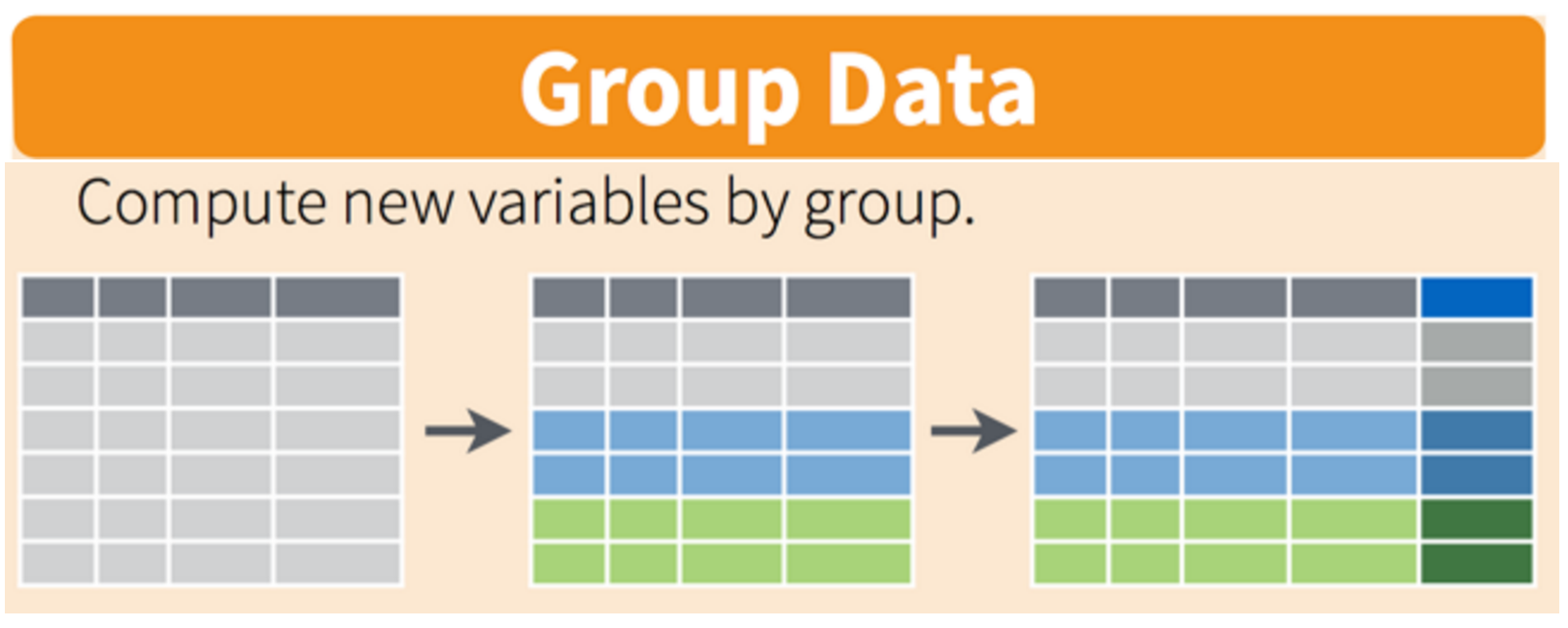
The group_by() function enables you to perform operations across groups within the data frame. It is typically used by inserting it in the “pipeline” before the desired group operation. For example, if we wanted to add a a new column that computed the mean height of reported wildlife impacts for each state, we could insert group_by(state) in the pipeline:
df %>%
filter(!is.na(height)) %>%
group_by(state) %>% # Here we're grouping by state
mutate(mean_height = mean(height)) %>%
select(state, mean_height)## [90m# A tibble: 38,940 x 2[39m
## [90m# Groups: state [59][39m
## state mean_height
## [3m[90m<chr>[39m[23m [3m[90m<dbl>[39m[23m
## [90m 1[39m FL 892.
## [90m 2[39m IN 719.
## [90m 3[39m FL 892.
## [90m 4[39m FL 892.
## [90m 5[39m TX [4m1[24m177.
## [90m 6[39m NY 937.
## [90m 7[39m N/A 994.
## [90m 8[39m N/A 994.
## [90m 9[39m MD [4m1[24m265.
## [90m10[39m CA 989.
## [90m# … with 38,930 more rows[39mYou’ll see that the same value for mean_height is reported for the same states (e.g. the mean height in Florida is 892 ft).
The summarize() function
The group_by() function is often used together with summarize(), which collapses each group into a single-row summary of that group. For example, we collapse the result of the previous example by using summarise() instead of mutate():
df %>%
filter(!is.na(height)) %>%
group_by(state) %>%
summarise(mean_height = mean(height))## `summarise()` ungrouping output (override with `.groups` argument)## [90m# A tibble: 59 x 2[39m
## state mean_height
## [3m[90m<chr>[39m[23m [3m[90m<dbl>[39m[23m
## [90m 1[39m AB 327.
## [90m 2[39m AK 334.
## [90m 3[39m AL 861.
## [90m 4[39m AR 968.
## [90m 5[39m AZ [4m2[24m134.
## [90m 6[39m BC 497.
## [90m 7[39m CA 989.
## [90m 8[39m CO 442.
## [90m 9[39m CT 811.
## [90m10[39m DC 963.
## [90m# … with 49 more rows[39mYou can also group by multiple columns - here let’s group by state and the airline:
df %>%
filter(!is.na(height)) %>%
group_by(state, operator) %>%
summarise(mean_height = mean(height))## `summarise()` regrouping output by 'state' (override with `.groups` argument)## [90m# A tibble: 213 x 3[39m
## [90m# Groups: state [59][39m
## state operator mean_height
## [3m[90m<chr>[39m[23m [3m[90m<chr>[39m[23m [3m[90m<dbl>[39m[23m
## [90m 1[39m AB AMERICAN AIRLINES 318.
## [90m 2[39m AB UNITED AIRLINES 350
## [90m 3[39m AK AMERICAN AIRLINES 0
## [90m 4[39m AK DELTA AIR LINES 414.
## [90m 5[39m AK UNITED AIRLINES 311.
## [90m 6[39m AL AMERICAN AIRLINES [4m1[24m038.
## [90m 7[39m AL DELTA AIR LINES 485.
## [90m 8[39m AL SOUTHWEST AIRLINES [4m1[24m020.
## [90m 9[39m AL UNITED AIRLINES 375
## [90m10[39m AR AMERICAN AIRLINES 508.
## [90m# … with 203 more rows[39mNotice that in the above examples I’ve kept the early filter to drop NAs. This is important when performing summarizing functions like mean() or sum(). If NAs are present, the result will also be NA:
df %>%
group_by(state) %>%
summarise(mean_height = mean(height))## `summarise()` ungrouping output (override with `.groups` argument)## [90m# A tibble: 59 x 2[39m
## state mean_height
## [3m[90m<chr>[39m[23m [3m[90m<dbl>[39m[23m
## [90m 1[39m AB [31mNA[39m
## [90m 2[39m AK 334.
## [90m 3[39m AL [31mNA[39m
## [90m 4[39m AR [31mNA[39m
## [90m 5[39m AZ [31mNA[39m
## [90m 6[39m BC [31mNA[39m
## [90m 7[39m CA [31mNA[39m
## [90m 8[39m CO [31mNA[39m
## [90m 9[39m CT [31mNA[39m
## [90m10[39m DC [31mNA[39m
## [90m# … with 49 more rows[39mOnce the data are grouped, you can also summarize multiple variables at the same time (and not necessarily on the same variable). For instance, you could add two more columns computing the minimum and maximum height:
df %>%
filter(!is.na(height)) %>%
group_by(state, operator) %>%
summarise(mean_height = mean(height),
min_height = min(height),
max_height = max(height))## `summarise()` regrouping output by 'state' (override with `.groups` argument)## [90m# A tibble: 213 x 5[39m
## [90m# Groups: state [59][39m
## state operator mean_height min_height max_height
## [3m[90m<chr>[39m[23m [3m[90m<chr>[39m[23m [3m[90m<dbl>[39m[23m [3m[90m<dbl>[39m[23m [3m[90m<dbl>[39m[23m
## [90m 1[39m AB AMERICAN AIRLINES 318. 0 [4m1[24m300
## [90m 2[39m AB UNITED AIRLINES 350 0 [4m1[24m400
## [90m 3[39m AK AMERICAN AIRLINES 0 0 0
## [90m 4[39m AK DELTA AIR LINES 414. 0 [4m1[24m700
## [90m 5[39m AK UNITED AIRLINES 311. 0 [4m1[24m200
## [90m 6[39m AL AMERICAN AIRLINES [4m1[24m038. 0 [4m1[24m[4m1[24m300
## [90m 7[39m AL DELTA AIR LINES 485. 0 [4m5[24m400
## [90m 8[39m AL SOUTHWEST AIRLINES [4m1[24m020. 0 [4m1[24m[4m0[24m000
## [90m 9[39m AL UNITED AIRLINES 375 0 [4m2[24m800
## [90m10[39m AR AMERICAN AIRLINES 508. 0 [4m3[24m400
## [90m# … with 203 more rows[39mCounting
Often times you will want to know the number of observations found for each variable or combination of variables. One way to do this is to use the group_by() and summarise() functions in combination. For example, here is the number of observations for each aircraft engine type:
df %>%
group_by(type_eng) %>%
summarise(count = n())## `summarise()` ungrouping output (override with `.groups` argument)## [90m# A tibble: 5 x 2[39m
## type_eng count
## [3m[90m<chr>[39m[23m [3m[90m<int>[39m[23m
## [90m1[39m A 2
## [90m2[39m C 34
## [90m3[39m D [4m5[24m[4m6[24m705
## [90m4[39m F 3
## [90m5[39m [31mNA[39m 234Since this is such a common task, dplyr provides the count() function to do the same thing:
df %>%
count(type_eng)## [90m# A tibble: 5 x 2[39m
## type_eng n
## [3m[90m<chr>[39m[23m [3m[90m<int>[39m[23m
## [90m1[39m A 2
## [90m2[39m C 34
## [90m3[39m D [4m5[24m[4m6[24m705
## [90m4[39m F 3
## [90m5[39m [31mNA[39m 234For convenience, count() also provides the sort argument:
df %>%
count(type_eng, sort = TRUE)## [90m# A tibble: 5 x 2[39m
## type_eng n
## [3m[90m<chr>[39m[23m [3m[90m<int>[39m[23m
## [90m1[39m D [4m5[24m[4m6[24m705
## [90m2[39m [31mNA[39m 234
## [90m3[39m C 34
## [90m4[39m F 3
## [90m5[39m A 2You can also count the combination of variables by providing more than one column name to count():
df %>%
count(type_eng, num_engs, sort = TRUE)## [90m# A tibble: 10 x 3[39m
## type_eng num_engs n
## [3m[90m<chr>[39m[23m [3m[90m<dbl>[39m[23m [3m[90m<int>[39m[23m
## [90m 1[39m D 2 [4m5[24m[4m3[24m652
## [90m 2[39m D 3 [4m2[24m753
## [90m 3[39m D 4 299
## [90m 4[39m [31mNA[39m [31mNA[39m 232
## [90m 5[39m C 2 34
## [90m 6[39m F 2 3
## [90m 7[39m [31mNA[39m 2 2
## [90m 8[39m A 1 1
## [90m 9[39m A 2 1
## [90m10[39m D [31mNA[39m 1Hmm, looks like most reported wildlife impacts involve planes with 2 D-type engines.
Exporting data
Now that you have learned how to use dplyr to extract information from or summarize your raw data, you may want to export these new data sets. Similar to the read_csv() function used for reading CSV files into R, there is a write_csv() function that generates CSV files from data frames.
Important: Before using write_csv(), create a new folder called “data_output” and put it in your R Project folder. In general, you should never write generated datasets in the same directory as your raw data. The “data” folder should only contain the raw, unaltered data, and should be left alone to make sure we don’t delete or modify it.
Let’s save one of the summary data frames from the earlier examples where we computed the min, mean, and max heights of impacts by each state and airline:
heightSummary <- df %>%
filter(!is.na(height)) %>%
group_by(state, operator) %>%
summarise(mean_height = mean(height),
min_height = min(height),
max_height = max(height))## `summarise()` regrouping output by 'state' (override with `.groups` argument)Save the the new heightSummary data frame as a CSV file in your “data_output” folder:
write_csv(heightSummary, path = file.path('data_output', 'heightSummary.csv')Tips
You will often need to create new variables based on a condition. To do this, you can use the if_else() function. Here’s the general syntax:
if_else(<condition>, <if TRUE>, <else>)The first argument is a condition. If the condition is TRUE, then the value given to the second argument will be used; if not, then the third argument value will be used.
Here’s an example of creating a variable to determine which months in the wildlife impacts data are in the summer:
df %>%
mutate(
summer_month = if_else(incident_month %in% c(6, 7, 8), TRUE, FALSE))Of course, in this particular case the if_else() function isn’t even needed because the condition returns TRUE and FALSE values. However, if you wanted to extend this example to determine all four seasons, you could use a series of nested if_else() functions:
df %>%
mutate(season =
if_else(
incident_month %in% c(3, 4, 5), 'Spring',
if_else(
incident_month %in% c(6, 7, 8), 'Summer',
if_else(
incident_month %in% c(9, 10, 11), 'Fall', 'Winter'))))Note: The Base R version of this function is ifelse(), but I recommend using the dplyr version, if_else(), as it is a stricter function.
Page sources:
Some content on this page has been modified from other courses, including:
- Data Analysis and Visualization in R for Ecologists, by François Michonneau & Auriel Fournier. Zenodo: http://doi.org/10.5281/zenodo.3264888
- The amazing illustrations by Allison Horst
Tuesdays | 12:45 - 3:15 PM | Dr. John Paul Helveston | jph@gwu.edu
Content 2020 John Paul Helveston. See the licensing page for details.